DataExtractorAI
Transform Unstructured Data into Actionable Intelligence. Automate data extraction from PDFs, HTML, and more with AI precision.
It started with a simple frustration
I was tired of copying data from PDFs by hand. This was back when AI was still kind of dumb—before it learned to follow instructions properly. Everyone was talking about “document intelligence,” but the reality was still a lot of manual work and praying your regex didn’t break.
So I built DataExtractorAI. Not because the world needed another extraction tool (AWS Textract and Google Document AI already existed), but because I wanted something I could actually use without writing a hundred lines of integration code (and I like new challenges).

Keep it simple, stupid
My stack wasn’t fancy. Laravel and Blade. That’s it. I know the cool kids were doing React and microservices, but I needed to ship something that worked, even if I was the only person who is going to use it. Laravel gave me everything: API routes, auth, queues, database—out of the box. Blade let me build a UI in an afternoon. It wasn’t about being cutting-edge; it was about being productive.
The goal was simple: make a playground where you could paste a document, define what you wanted in plain English, and get structured JSON back. No SDKs. Just results.
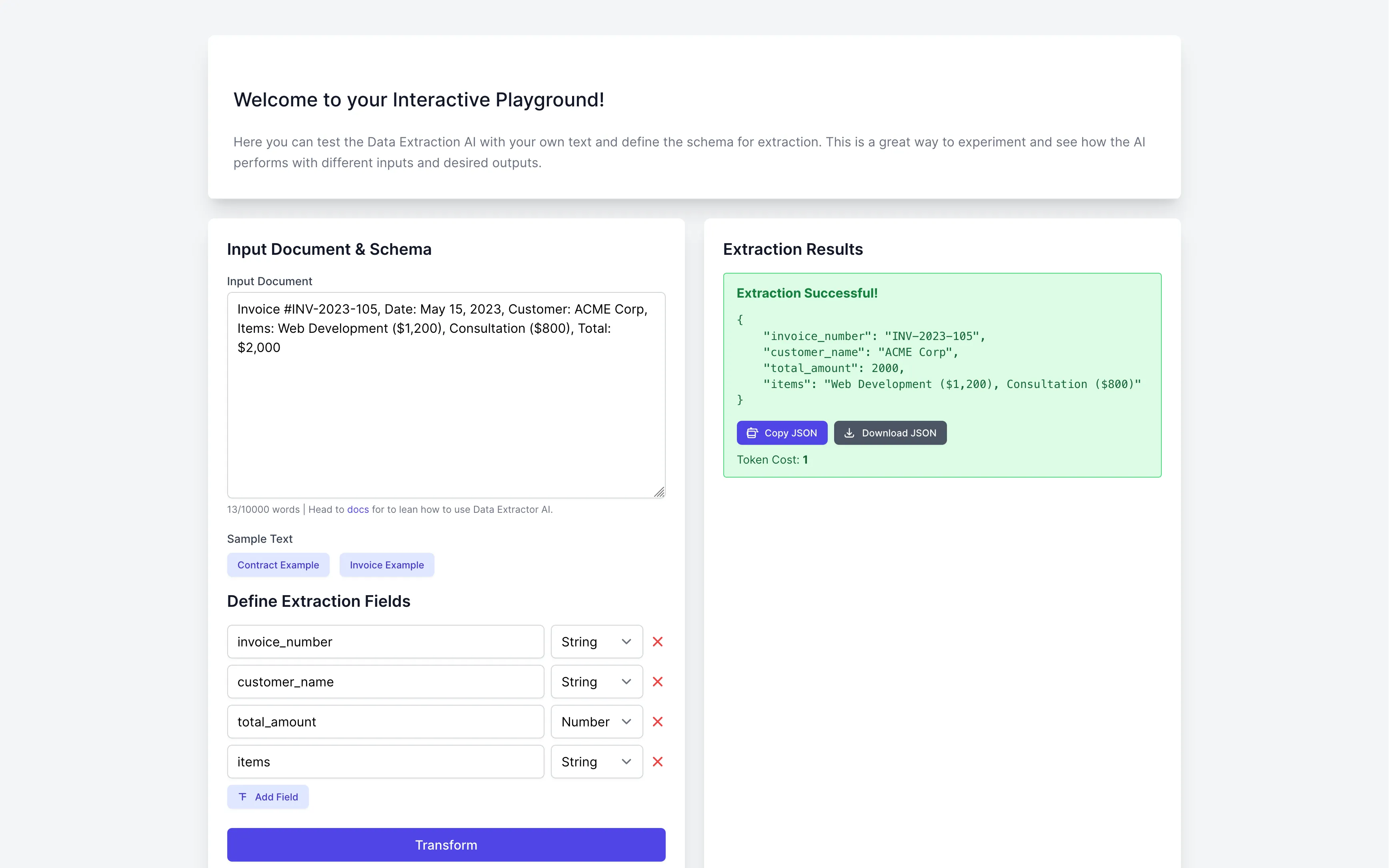
Then GPT-3.5 actually delivered
When OpenAI dropped GPT-3.5 with proper JSON output support, the game changed. Suddenly I could tell the AI “give me invoice numbers, dates, and line items in this exact format” and it mostly worked. The dream of reliable AI extraction wasn’t just a dream anymore.
But here’s the thing: “mostly works” isn’t good enough when you’re building a tool people might actually use. The AI would hallucinate fields, misread tables, or just confidently return garbage. dataextractorai.com shows a clean demo of invoice processing, but behind that simplicity was a lot of prompting.
I ended up building layers of validation: JSON Schema enforcement, retry logic with JSON healing, and fallback rules for when the AI inevitably got confused. I was aiming for at least 90% accuracy, but getting there meant assuming the AI would fail at least 10% of the time and planning for it.
What I actually learned
JSON Schema is your best friend. If you’re not validating AI output against a strict schema, you’re just begging for production incidents. It’s not overkill—it’s mandatory.
Trust, but verify. AI is confident even when it’s dead wrong. Building DataExtractorAI taught me that blind faith in model outputs is professional suicide. Always check the work.
Developer experience matters more than tech hype. Nobody cares if you’re using the latest framework. They care if they can get their job done in five minutes without reading documentation.
Edge cases are the real product. The happy path is easy. The real work is handling that one weird PDF format from Adobe Acrobat 1997 that some companies still use.
The project’s archived now—AI moved forward and so did I. But the lessons stuck. Don’t build for the cool factor. Build for the thousand ways it’ll break in production.